Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
Al trabajar con documentos, es importante poder extraer fácilmente contenido de un rango específico dentro de un documento. Sin embargo, el contenido puede consistir en elementos complejos como párrafos, tablas, imágenes, etc.
Independientemente del contenido que deba extraerse, el método para extraer ese contenido siempre estará determinado por los nodos seleccionados para extraer contenido entre ellos. Estos pueden ser cuerpos de texto completos o ejecuciones de texto simples.
Hay muchas situaciones posibles y, por lo tanto, muchos tipos de nodos diferentes a considerar al extraer contenido. Por ejemplo, es posible que desee extraer contenido entre:
En algunas situaciones, es posible que incluso necesite combinar diferentes tipos de nodos, como extraer contenido entre un párrafo y un campo, o entre una ejecución y un marcador.
Este artículo proporciona la implementación del código para extraer texto entre diferentes nodos, así como ejemplos de escenarios comunes.
A menudo, el objetivo de extraer el contenido es duplicarlo o guardarlo por separado en un nuevo documento. Por ejemplo, puede extraer contenido y:
Esto se puede lograr fácilmente usando Aspose.Words y la implementación del código a continuación.
El código de esta sección aborda todas las situaciones posibles descritas anteriormente con un método generalizado y reutilizable. El esquema general de esta técnica involucra:
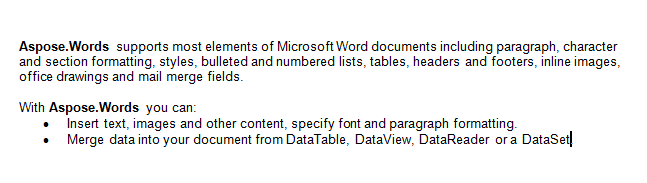
Trabajaremos con el documento a continuación en este artículo. Como puede ver, contiene una variedad de contenido. También tenga en cuenta que el documento contiene una segunda sección que comienza en el medio de la primera página. Un marcador y un comentario también están presentes en el documento, pero no son visibles en la captura de pantalla a continuación.

Para extraer el contenido de su documento, debe llamar al método ExtractContent a continuación y pasar los parámetros apropiados.
La base subyacente de este método implica encontrar nodos a nivel de bloque (párrafos y tablas) y clonarlos para crear copias idénticas. Si los nodos marcadores pasados son de nivel de bloque, entonces el método puede simplemente copiar el contenido en ese nivel y agregarlo a la matriz.
Sin embargo, si los nodos marcadores están en línea (un elemento secundario de un párrafo), la situación se vuelve más compleja, ya que es necesario dividir el párrafo en el nodo en línea, ya sea una ejecución, campos de marcadores, etc. Se elimina el contenido de los nodos primarios clonados que no está presente entre los marcadores. Este proceso se utiliza para garantizar que los nodos en línea conserven el formato del párrafo principal.
El método también ejecutará comprobaciones en los nodos pasados como parámetros y lanzará una excepción si alguno de los nodos no es válido. Los parámetros que se pasarán a este método son:
StartNode y EndNode. Los dos primeros parámetros son los nodos que definen dónde debe comenzar y finalizar la extracción del contenido, respectivamente. Estos nodos pueden ser tanto de nivel de bloque (Paragraph, Table) como de nivel en línea (por ejemplo Run, FieldStart, BookmarkStart etc.):
IsInclusive. Define si los marcadores están incluidos en la extracción o no. Si esta opción se establece en false y se pasan el mismo nodo o nodos consecutivos, se devolverá una lista vacía:
La implementación del método ExtractContent puede encontrar aquí. Este método se mencionará en los escenarios de este artículo.
También definiremos un método personalizado para generar fácilmente un documento a partir de nodos extraídos. Este método se usa en muchos de los escenarios a continuación y simplemente crea un nuevo documento e importa el contenido extraído en él.
El siguiente ejemplo de código muestra cómo tomar una lista de nodos e insertarlos en un nuevo documento:
Esto demuestra cómo usar el método anterior para extraer contenido entre párrafos específicos. En este caso, queremos extraer el cuerpo de la carta que se encuentra en la primera mitad del documento. Podemos decir que esto está entre los párrafos 7 y 11.
El código a continuación cumple esta tarea. Los párrafos apropiados se extraen utilizando el método getChild en el documento y pasando los índices especificados. Luego pasamos estos nodos al método ExtractContent y establecemos que se incluirán en la extracción. Este método devolverá el contenido copiado entre estos nodos que luego se insertarán en un nuevo documento.
El siguiente ejemplo de código muestra cómo extraer el contenido entre párrafos específicos utilizando el método ExtractContent anterior:
El documento de salida contiene los dos párrafos que se extrajeron.
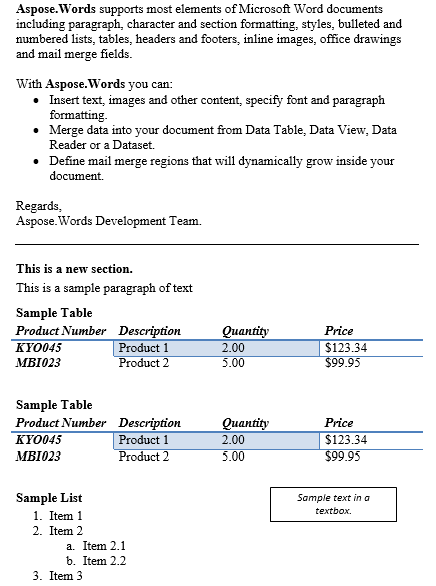
Podemos extraer contenido entre cualquier combinación de nodos a nivel de bloque o en línea. En este escenario a continuación, extraeremos el contenido entre el primer párrafo y la tabla en la segunda sección inclusive. Obtenemos los nodos marcadores llamando al método getFirstParagraph y getChild en la segunda sección del documento para recuperar los nodos Paragraph y Table apropiados. Para una ligera variación, dupliquemos el contenido e insértelo debajo del original.
El siguiente ejemplo de código muestra cómo extraer el contenido entre un párrafo y una tabla utilizando el método ExtractContent:
El contenido entre el párrafo y la tabla se ha duplicado a continuación es el resultado.
Es posible que deba extraer el contenido entre párrafos del mismo estilo o de un estilo diferente, como entre párrafos marcados con estilos de encabezado.
El siguiente código muestra cómo lograr esto. Es un ejemplo simple que extraerá el contenido entre la primera instancia de los estilos" Heading 1 “y” Encabezado 3 " sin extraer también los encabezados. Para hacer esto, establecemos el último parámetro en false, que especifica que los nodos marcadores no deben incluirse.
En una implementación adecuada, esto debe ejecutarse en un bucle para extraer contenido entre todos los párrafos de estos estilos del documento. El contenido extraído se copia en un nuevo documento.
El siguiente ejemplo de código muestra cómo extraer contenido entre párrafos con estilos específicos utilizando el método ExtractContent:
A continuación se muestra el resultado de la operación anterior.

También puede extraer contenido entre nodos en línea, como a Run. Runs de diferentes párrafos se pueden pasar como marcadores. El siguiente código muestra cómo extraer texto específico entre el mismo nodo Paragraph.
El siguiente ejemplo de código muestra cómo extraer contenido entre ejecuciones específicas del mismo párrafo utilizando el método ExtractContent:
El texto extraído se muestra en la consola.
Para usar un campo como marcador, se debe pasar el nodo FieldStart. El último parámetro del método ExtractContent definirá si se debe incluir o no todo el campo. Extraigamos el contenido entre el campo de combinación" FullName " y un párrafo del documento. Usamos el método moveToMergeField de la clase DocumentBuilder. Esto devolverá el nodo FieldStart del nombre del campo de combinación que se le pasó.
En nuestro caso, establezcamos el último parámetro pasado al método ExtractContent en falso para excluir el campo de la extracción. Renderizaremos el contenido extraído a PDF.
El siguiente ejemplo de código muestra cómo extraer contenido entre un campo y un párrafo específicos en el documento utilizando el método ExtractContent:
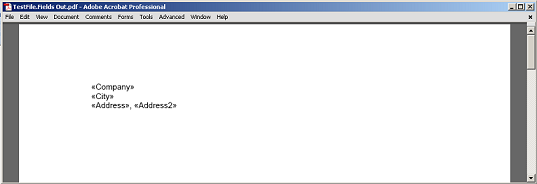
El contenido extraído entre el campo y el párrafo, sin los nodos marcadores de campo y párrafo representados en PDF.
En un documento, el contenido definido dentro de un marcador está encapsulado por los nodos BookmarkStart y BookmarkEnd. El contenido que se encuentra entre estos dos nodos forma el marcador. Puede pasar cualquiera de estos nodos como cualquier marcador, incluso los de marcadores diferentes, siempre que el marcador inicial aparezca antes del marcador final en el documento.
En nuestro documento de muestra, tenemos un marcador, llamado “Marcador1”. El contenido de este marcador es contenido resaltado en nuestro documento:
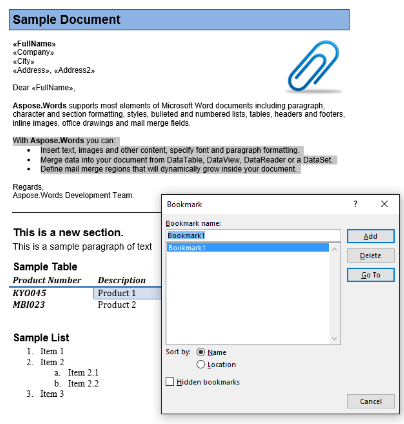
Extraeremos este contenido en un nuevo documento usando el código a continuación. La opción de parámetro IsInclusive muestra cómo conservar o descartar el marcador.
El siguiente ejemplo de código muestra cómo extraer el contenido al que se hace referencia en un marcador mediante el método ExtractContent:
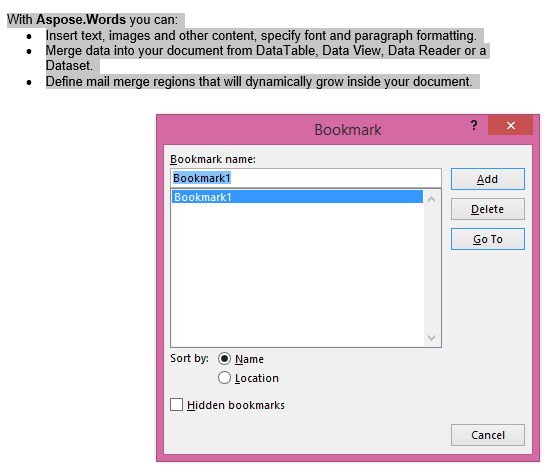
La salida extraída con el parámetro IsInclusive establecido en verdadero. La copia también conservará el marcador.
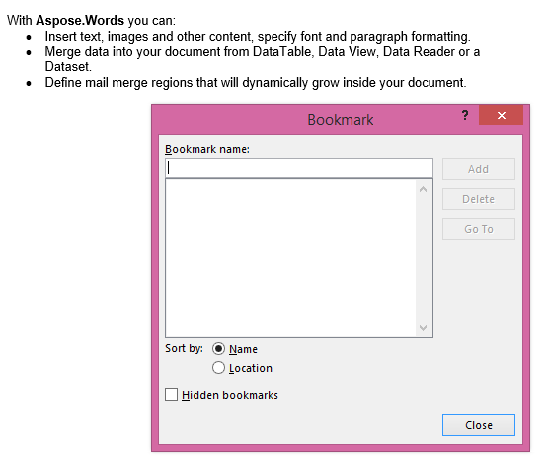
La salida extraída con el parámetro IsInclusive establecido en falso. La copia contiene el contenido pero sin el marcador.
Un comentario está formado por los nodos CommentRangeStart, CommentRangeEnd y Comentario. Todos estos nodos están en línea. Los dos primeros nodos encapsulan el contenido en el documento al que hace referencia el comentario, como se ve en la captura de pantalla a continuación.
El nodo Comment en sí mismo es un InlineStory que puede contener párrafos y ejecuciones. Representa el mensaje del comentario visto como una burbuja de comentarios en el panel de revisión. Como este nodo está en línea y es descendiente de un cuerpo, también puede extraer el contenido de este mensaje.
En nuestro documento tenemos un comentario. Mostrémoslo mostrando el marcado en la pestaña Revisar:
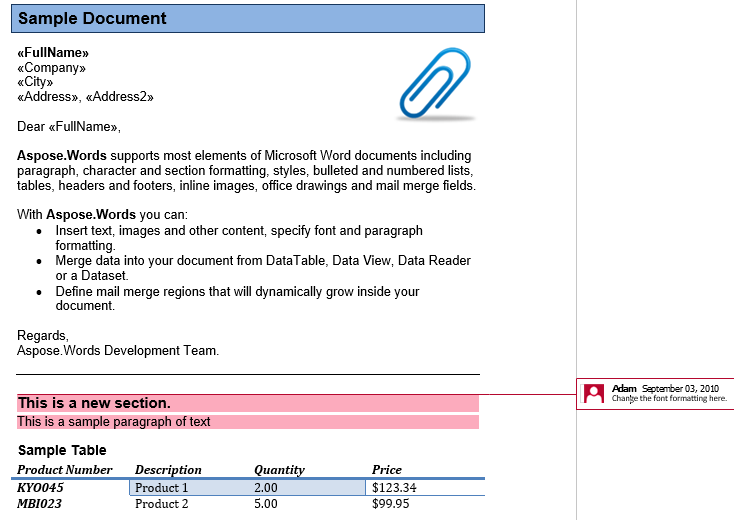
El comentario encapsula el encabezado, el primer párrafo y la tabla en la segunda sección. Extraigamos este comentario en un nuevo documento. La opción IsInclusive determina si el comentario en sí se mantiene o se descarta.
El siguiente ejemplo de código muestra cómo hacer esto a continuación:
En primer lugar, la salida extraída con el parámetro IsInclusive establecido en verdadero. La copia también contendrá el comentario.
En segundo lugar, la salida extraída con isInclusive establecido en falso. La copia contiene el contenido pero sin el comentario.

Aspose.Words se puede utilizar no solo para crear documentos Microsoft Word construyéndolos dinámicamente o fusionando plantillas con datos, sino también para analizar documentos con el fin de extraer elementos separados del documento, como encabezados, pies de página, párrafos, tablas, imágenes y otros. Otra tarea posible es encontrar todo el texto de formato o estilo específico.
Utilice la clase DocumentVisitor para implementar este escenario de uso. Esta clase corresponde al conocido patrón de diseño de visitantes. Con DocumentVisitor, puede definir y ejecutar operaciones personalizadas que requieran enumeración en el árbol de documentos.
DocumentVisitor proporciona un conjunto de VisitXXX métodos que se invocan cuando se encuentra un elemento de documento (nodo) en particular. Por ejemplo, se llama a VisitParagraphStart cuando se encuentra el principio de un párrafo de texto y se llama a VisitParagraphEnd cuando se encuentra el final de un párrafo de texto. Cada método DocumentVisitor.VisitXXX acepta el objeto correspondiente que encuentra para que pueda usarlo según sea necesario (digamos recuperar el formato), por ejemplo, tanto VisitParagraphStart como VisitParagraphEnd aceptan un objeto Paragraph.
Cada método DocumentVisitor.VisitXXX devuelve un valor VisitorAction que controla la enumeración de nodos. Puede solicitar continuar la enumeración, omitir el nodo actual (pero continuar con la enumeración) o detener la enumeración de nodos.
Estos son los pasos que debe seguir para determinar y extraer mediante programación varias partes de un documento:
DocumentVisitor proporciona implementaciones predeterminadas para todos los DocumentVisitor.VisitXXX métodos. Esto facilita la creación de nuevos visitantes de documentos, ya que solo se deben anular los métodos necesarios para el visitante en particular. No es necesario anular todos los métodos de visitante.
El siguiente ejemplo muestra cómo usar el patrón de visitante para agregar nuevas operaciones al modelo de objetos Aspose.Words. En este caso, creamos un convertidor de documentos simple a un formato de texto:
Las formas de recuperar texto del documento son:
SaveFormat.Text. Internamente, esto invoca guardar como texto en una secuencia de memoria y devuelve la cadena resultanteNode.GetText y Node.ToStringUn documento de Word puede contener caracteres de control que designen elementos especiales como campo, final de celda, final de sección, etc. La lista completa de posibles caracteres de control de palabras se define en la clase ControlChar. El método GetText devuelve texto con todos los caracteres de carácter de control presentes en el nodo.
Llamar a ToString devuelve la representación de texto sin formato del documento solo sin caracteres de control. Para obtener más información sobre cómo exportar como texto sin formato, consulte Using SaveFormat.Text.
El siguiente ejemplo de código muestra la diferencia entre llamar a los métodos GetText y ToString en un nodo:
SaveFormat.TextEste ejemplo guarda el documento de la siguiente manera:
El siguiente ejemplo de código muestra cómo guardar un documento en formato TXT:
Es posible que deba extraer imágenes de documentos para realizar algunas tareas. Aspose.Words también te permite hacer esto.
El siguiente ejemplo de código muestra cómo extraer imágenes de un documento:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.