Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
This page explains the in-memory Document Object Model (DOM) provided by Aspose.Words for navigating and modifying Word documents programmatically.
The Aspose.Words Document Object Model (DOM) is an in-memory representation of a Word document. The Aspose.Words DOM allows you to programmatically read, manipulate, and modify the content and formatting of a Word document.
This section describes the main classes of the Aspose.Words DOM and their relationships. By using the Aspose.Words DOM classes, you can obtain programmatic access to document elements and formatting.
Document Object Tree
When a document is read into the Aspose.Words DOM, then an object tree is built and different types of elements of the source document have their own DOM tree objects with various properties.
When Aspose.Words reads a Word document into memory, it creates objects of different types that represent various document elements. Every run of a text, paragraph, table, or a section is a node, and even the document itself is a node. Aspose.Words defines a class for every document node type.
The document tree in Aspose.Words follows the Composite Design Pattern:
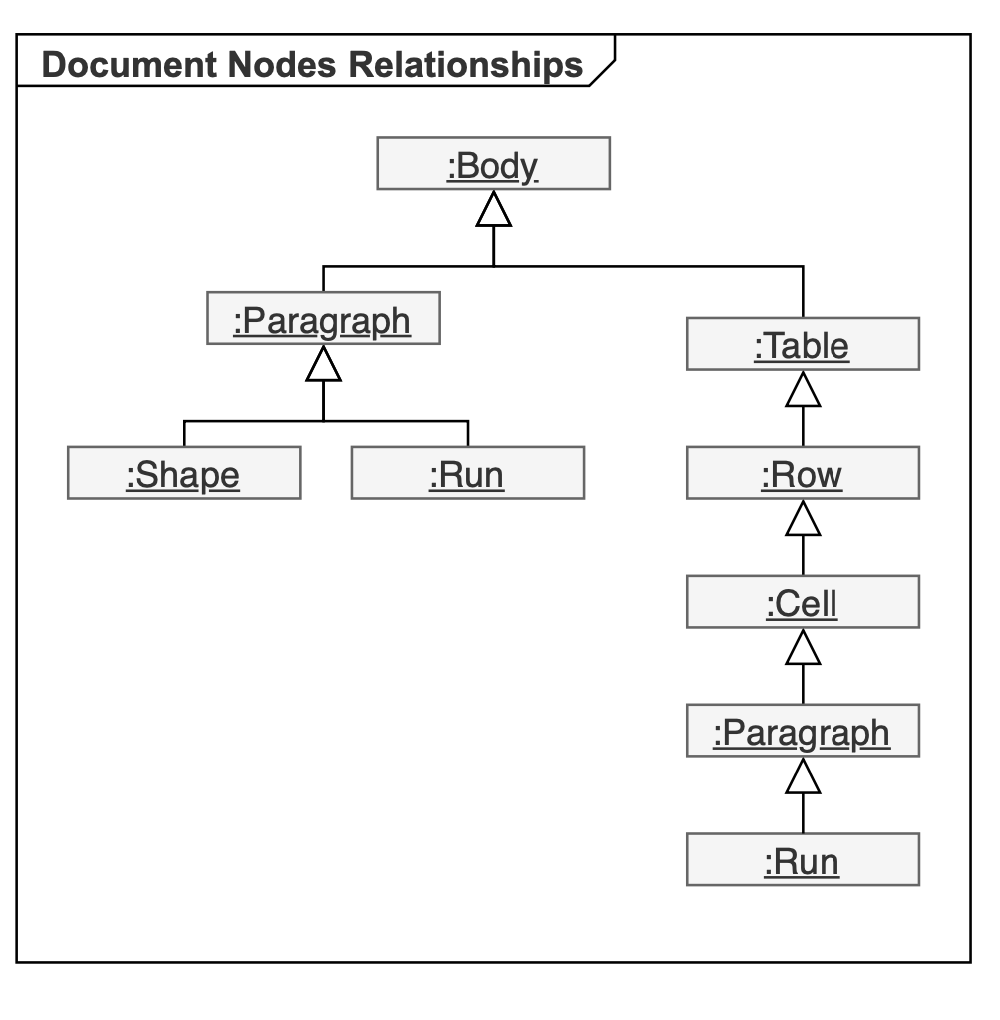
The diagram provided below shows inheritance between node classes of the Aspose.Words Document Object Model (DOM). The names of abstract classes are in Italics.
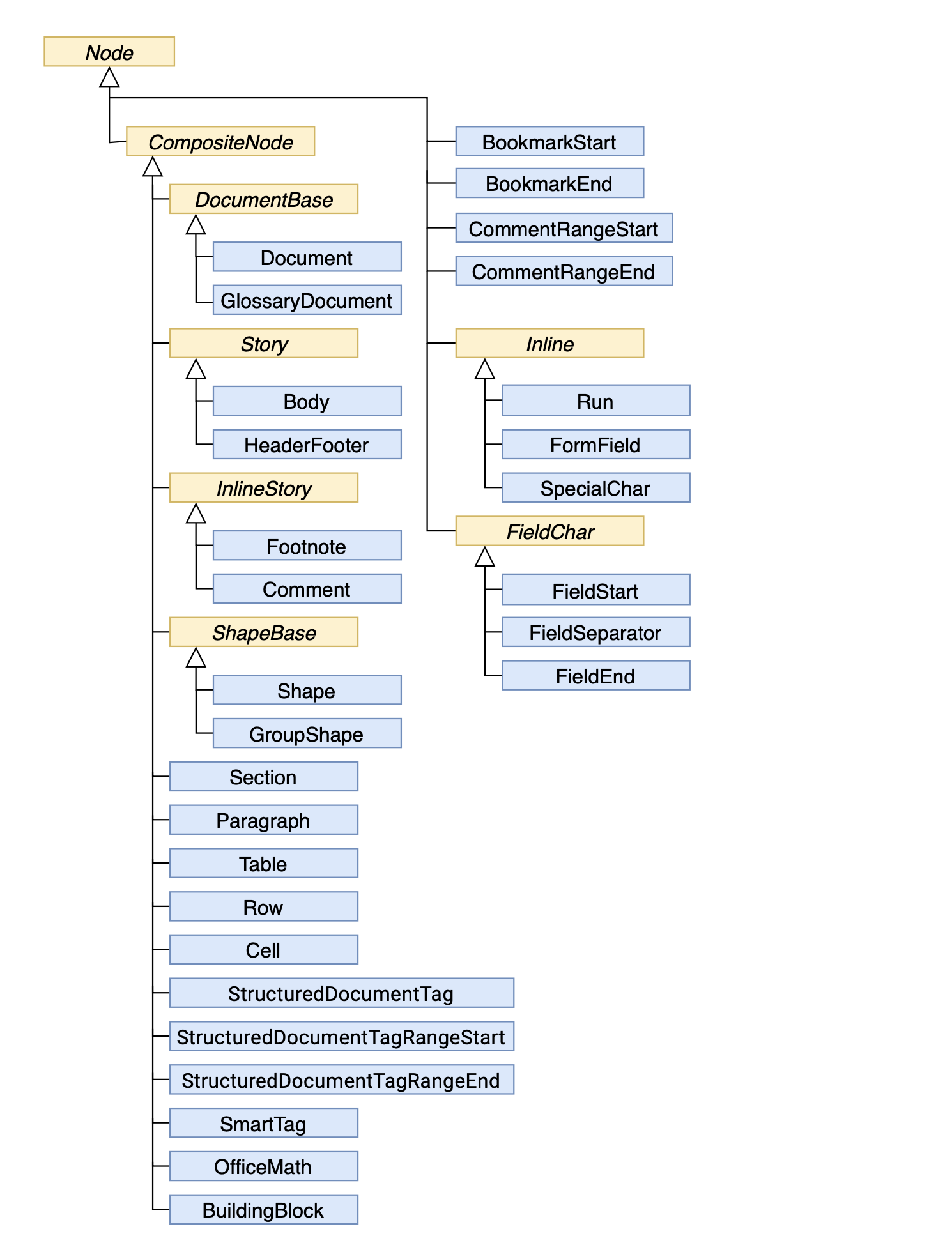
Node class.
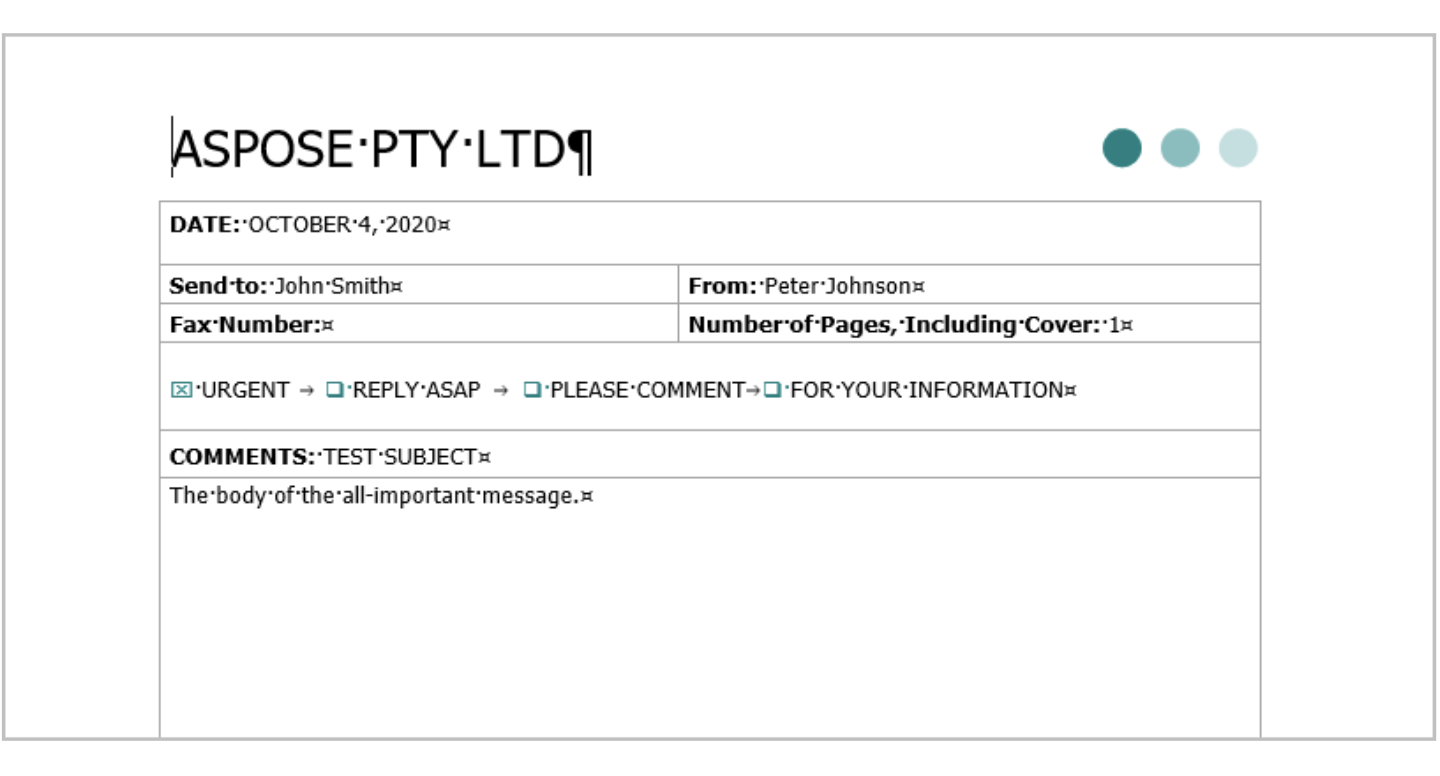
Let’s look at an example. The following image shows a Microsoft Word document with different types of content.
When reading the above document into the Aspose.Words DOM, the tree of objects is created, as shown in the schema below.
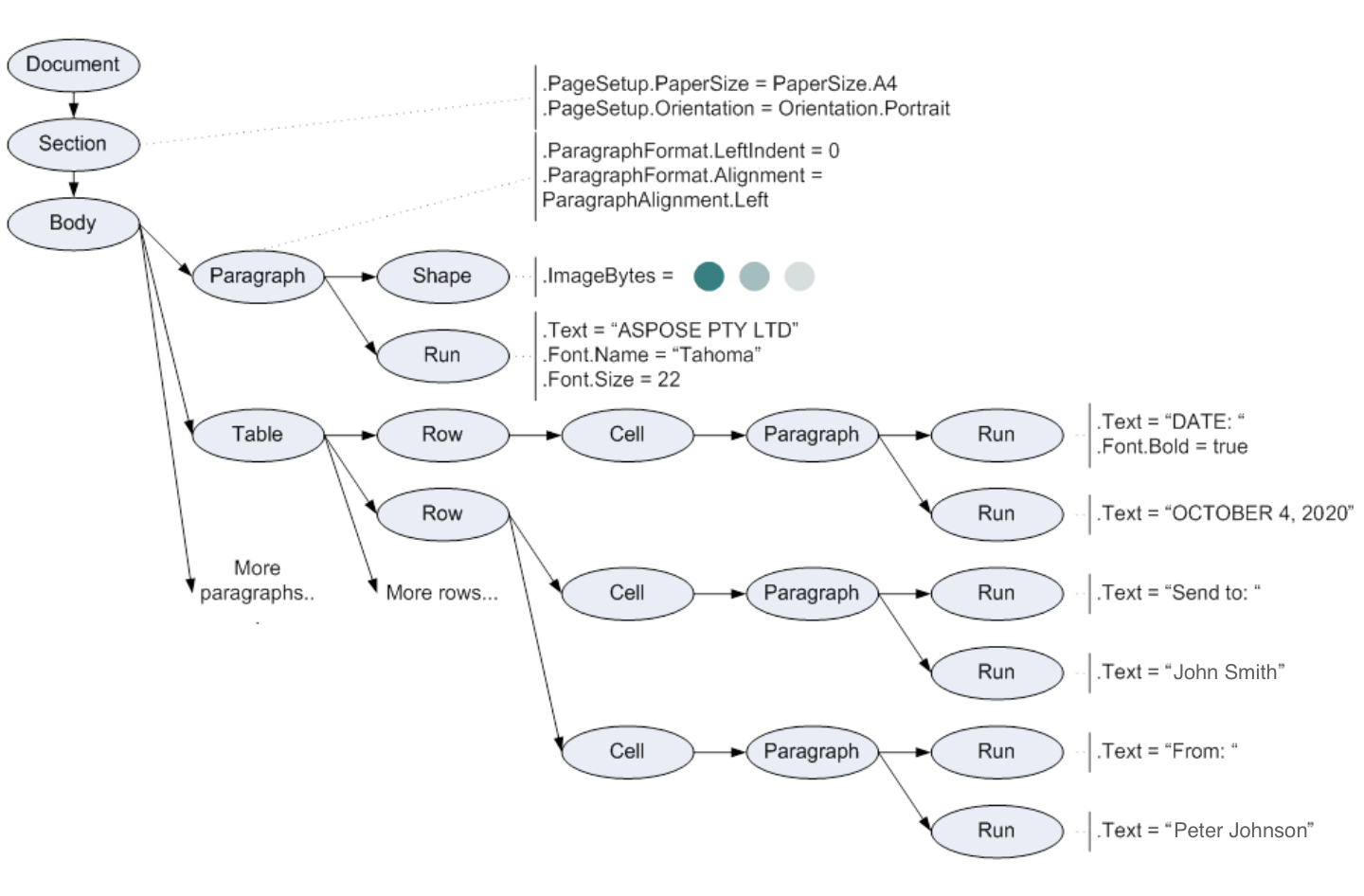
Document, Section, Paragraph, Table, Shape, Run, and all other ellipses on the diagram are Aspose.Words objects that represent elements of the Word document.
Node Type
Although the Node class is sufficient enough to distinguish different nodes from each other, Aspose.Words provides the NodeType enumeration to simplify some API tasks, such as selecting nodes of a specific type.
The type of each node can be obtained using the NodeType property. This property returns a NodeType enumeration value. For example, a paragraph node represented by the Paragraph class returns NodeType.Paragraph, and a table node represented by the Table class returns NodeType.Table.
The following example shows how to get a node type using the NodeType enumeration:
Aspose.Words represents a document as a node tree, which enables you to navigate between nodes. This section describes how to explore and navigate the document tree in Aspose.Words.
When you open the sample document, presented earlier, in the Document Explorer, the node tree appears exactly as it is represented in Aspose.Words.
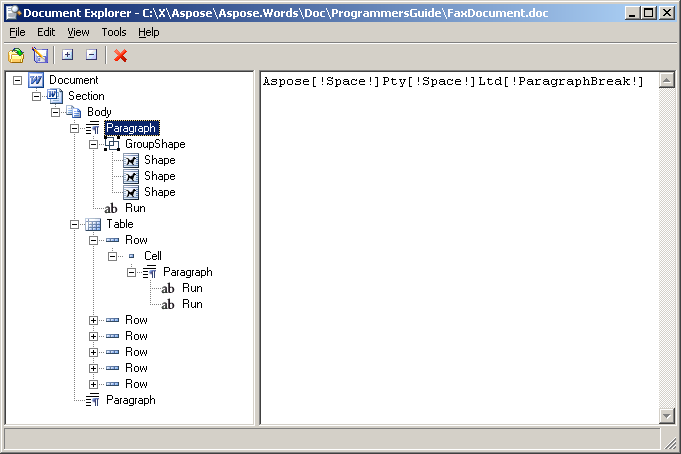
The nodes in the tree have relationships between them:
The nodes that can contain other nodes derive from the CompositeNode class, and all nodes ultimately derive from the Node class. These two base classes provide common methods and properties for the tree structure navigation and modification.
The following UML object diagram shows several nodes of the sample document and their relations to each other via the parent, child, and sibling properties:
A node always belongs to a particular document, even if it has been just created or removed from the tree, because vital document-wide structures such as styles and lists are stored in the Document node. For example, it is not possible to have a Paragraph without a Document because each paragraph has an assigned style that is defined globally for the document. This rule is used when creating any new nodes. Adding a new Paragraph directly to the DOM requires a document object passed to the constructor.
When creating a new paragraph using DocumentBuilder, the builder always has a Document class linked to it through the DocumentBuilder.Document property.
The following code example shows that when creating any node, a document that will own the node is always defined:
Each node has a parent specified by the ParentNode property. A node has no parent node, that is, ParentNode is null, in the following cases:
You can remove a node from its parent by calling the Remove method.The following code example shows how to access the parent node:
The most efficient way to access child nodes of a CompositeNode is via the FirstChild and LastChild properties that return the first and last child nodes, respectively. If there are no child nodes, these properties return null.
CompositeNode also provides the GetChildNodes method enabling indexed or enumerated access to the child nodes. The ChildNodes property is a live collection of nodes, which means that whenever the document is changed, such as when nodes are removed or added, the ChildNodes collection is automatically updated.
If a node has no child, then the ChildNodes property returns an empty collection. You can check whether the CompositeNode contains any child nodes using the HasChildNodes property.
The following code example shows how to enumerate immediate child nodes of a CompositeNode using the enumerator provided by the ChildNodes collection:
You can obtain the node that immediately precedes or follows a particular node using the PreviousSibling and NextSibling properties, respectively. If a node is the last child of its parent, then the NextSibling property is null. Conversely, if the node is the first child of its parent, the PreviousSibling property is null.
The following code example shows how to efficiently visit all direct and indirect child nodes of a composite node:
So far, we have discussed the properties that return one of the base types – Node or CompositeNode. But sometimes there are situations where you might need to cast values to a specific node class, such as Run or Paragraph. That is, you cannot completely get away from casting when working with the Aspose.Words DOM, which is composite.
To reduce the need for casting, most Aspose.Words classes provide properties and collections that provide strongly typed access. There are three basic patterns of typed access:
Typed properties are merely useful shortcuts that sometimes provide easier access than generic properties inherited from Node.ParentNode and CompositeNode.FirstChild.
The following code example shows how to use typed properties to access nodes of the document tree:
Q: How can I create a Document object directly from a memory stream?
A: Use the Document(Stream) constructor. Pass a MemoryStream that contains the DOCX, PDF, or any supported format bytes. The stream must be positioned at the beginning before creating the document.
Q: What is the best way to move a node (e.g., a paragraph) into a header or footer?
A: Retrieve the target HeaderFooter node via Section.HeadersFooters[HeaderFooterType.HeaderPrimary] (or FooterPrimary) and call AppendChild(node) on that header/footer. The moved node automatically updates its ParentNode reference.
Q: How do I add a custom font to a document when the font is not installed on the system?
A: Load the font file into a FontSettings object with SetFontsFolder(path, false), assign the FontSettings to Document.FontSettings, and then apply the font name to a Run.Font.Name.
Q: How can I determine whether a document contains any visible text?
A: Iterate through all Run nodes using document.GetChildNodes(NodeType.Run, true) and check Run.Text.Trim().Length. If no run contains non‑whitespace text, the document is effectively empty.
Q: How do I use FindReplaceOptions to replace text only inside tables?
A: Create a FindReplaceOptions instance, set FindReplaceOptions.MatchCase = true (or other options), and assign a NodeChangingCallback that checks node.ParentNode is Cell. Then call document.Range.Replace("old", "new", options).
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.